|
| <-- Back to Previous Page | TOC | Next Section --> |
Chapter 4: The Synthesis of Sound by ComputerSection 4.4: Formant
Synthesis
|
||
Formant synthesis is a special but important case of subtractive synthesis. Part of what makes the timbre of a voice or instrument consistent over a wide range of frequencies is the presence of fixed frequency peaks, called formants. These peaks stay in the same frequency range, independent of the actual (fundamental) pitch being produced by the voice or instrument. While there are many other factors that go into synthesizing a realistic timbre, the use of formants is one way to get reasonably accurate results.
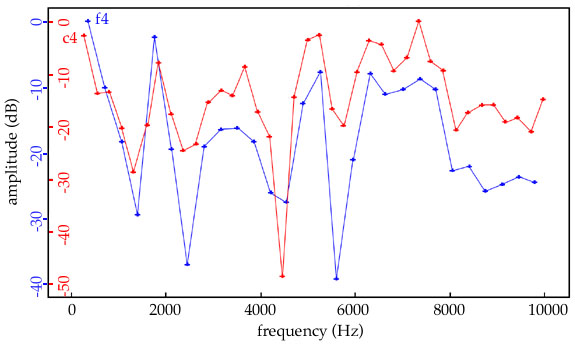
Figure 4.10 A
trumpet plays two different notes, a perfect fourth apart, but the formants
(fixed resonances) stay in the same places. |
||
Resonant StructureThe location of formants is based on the resonant physical structure
of the sound-producing medium. For example, the body of a certain violin
exhibits a particular set of formants, depending upon how it is constructed.
Since most violins share a similar shape and internal construction, they
share a similar set of formants and thus sound alike. In the human voice,
the vocal tract and nasal cavity act as the resonating body. By manipulating
the shape and size of that resonant space (i.e., by changing the shape
of the mouth and throat), we change the location of the formants in our
voice. We recognize different vowel sounds mainly by their formant placement.
Knowing that, we can generate some fairly convincing synthetic vowels
by manipulating formants in a synthesized set of tones. A number of books
list actual formant frequency values for various voices and vowels (including
Charles Dodge’s highly recommended standard text, Computer Music—Dodge
is a great pioneer in computer music voice synthesis). |
||
|
|
Composing with Synthetic SpeechGenerating really good and convincing synthetic speech and singing voices is more complex than simply moving around a set of formants—we haven’t mentioned anything about generating consonants, for example. And no speech synthesis system relies purely on formant synthesis. But, as these examples illustrate, even very basic formant manipulation can generate sounds that are undoubtedly "vocal" in nature.
Figure 4.11 A spectral picture of the voice, showing formants. Graphic courtesy of the alt.usage.english newsgroup. |
|
|
|
Figure 4.12 Composer
Paul Lansky. |
|
| |
||
|
|
"Notjustmoreidlechatter" was made on a DEC MicroVaxII computer in 1988. All the "chatter" pieces (there are three in the set) use techniques known as linear predictive coding, granular synthesis, and a variety of stochastic mixing techniques. Paul Lansky is a well-known composer and researcher of computer music who teaches at Princeton University. He has been a leading pioneer in software design, voice synthesis, and compositional techniques. Used with permission from Paul Lansky. |
|
| |
||
|
|
Paul Lansky writes: "Over ten years ago I wrote three 'chatter' pieces, and then decided to quit while I was ahead. The urge to strike again recently overtook me, however, and after my lawyer assured me that the statute of limitations had run out on this particular offense, I once again leapt into the fray. My hope is that the seasoning provided by my labors in the intervening years results in something new and different. If not, then look out for 'Idle Chatter III'... ." Used with permission from Paul Lansky. |
|
| |
||
|
|
Composer Sarah Myers used an interview with her friend Gili Rei as the source material for her composition. "Trajectory of Her Voice" is a ten-part canon that explores the musical qualities of speech. As the verbal content becomes progressively less comprehensible as language, the focus turns instead to the sonorities inherent in her voice. This piece was composed using the Cmix computer music language in 1998 (Cmix was written by Paul Lansky). |
|
| |
||
|
|
Over the years, computer voice simulations have become better and better. They still sound a bit robotic, but advances in voice synthesis and acoustic technology make voices more and more realistic. Bell Telephone Laboratories has been one of the leading research facilities for this work, which is expected to become extremely important in the near future. |
|
| |
||
|
|
In this piece, based on a reading by Australian sound-poet Chris Mann, the composer tries to separate vowels and consonants, moving them each to a different speaker. This was inspired by an idea of Mann's, who always wanted to do a "headphone piece" in which he spoke and the consonants appeared in one ear, the vowels in another. |
|
| |
||
|
|
One of the most interesting examples of formant usage is in playing the trump, sometimes called the jaw-harp. Here, a metal tine is plucked and the shape of the vocal cavity is used to create different pitches. |
|
| <-- Back to Previous Page | Next Section --> |
©Burk/Polansky/Repetto/Roberts/Rockmore. All rights reserved.